



There’s a lot of excitement around open-source language models right now—and for good reason. Llama 3, Mistral, Mixtral, Gemma... every week the community delivers something faster, cheaper, more powerful.
But if you’ve tried bringing these models into a real enterprise environment—where users span departments, data is sensitive, and compliance isn’t optional—you’ve likely hit a wall. A frustrating, architectural wall. One that no benchmark can solve.
You can host the model. You can run the model. But can you operate the model—safely, consistently, and across multiple users—without writing a new AI platform from scratch?
That’s the gap we’ve set out to close with Scalytics Connect.
The Dream vs. Reality of Self-Hosting LLMs
Everyone loves the idea of running models like Llama 3 locally: full control, no API costs, no vendor lock-in. But it only takes a few days in production before the friction starts:
- You can’t support more than one active user without race conditions or dropped contexts.
- You can’t enforce a system prompt to lock model behavior.
- You can’t control prompt lengths, output sizes, or summarize long histories reliably.
- You can’t track which user did what—or explain how a model got to its answer.
- And you can’t stop someone from accidentally routing customer data to a model that shouldn’t have access to it.
That’s because today’s tooling—Ollama, LM Studio, local vLLM setups—is built for individual developers, not enterprise environments.
They give you model execution.
We give you model operations.
So, Why Scalytics Connect?
Scalytics Connect is a purpose-built runtime designed for securely operating open-source LLMs in multi-user, policy-constrained enterprise environments. It gives you the building blocks that LLM hosting tools lack:
- Session-aware queuing and request isolation
- Centralized system prompt enforcement
- Intelligent context window management
- Global privacy controls
- Full audit trails for every inference
- Enterprise-ready API and dashboard controls
It’s the runtime layer you need when “just running the model” is no longer good enough.
We’re not trying to be a playground.
We’re building the control plane for secure, explainable, private LLMs in production.
Let’s walk through the key design decisions that brought us here.
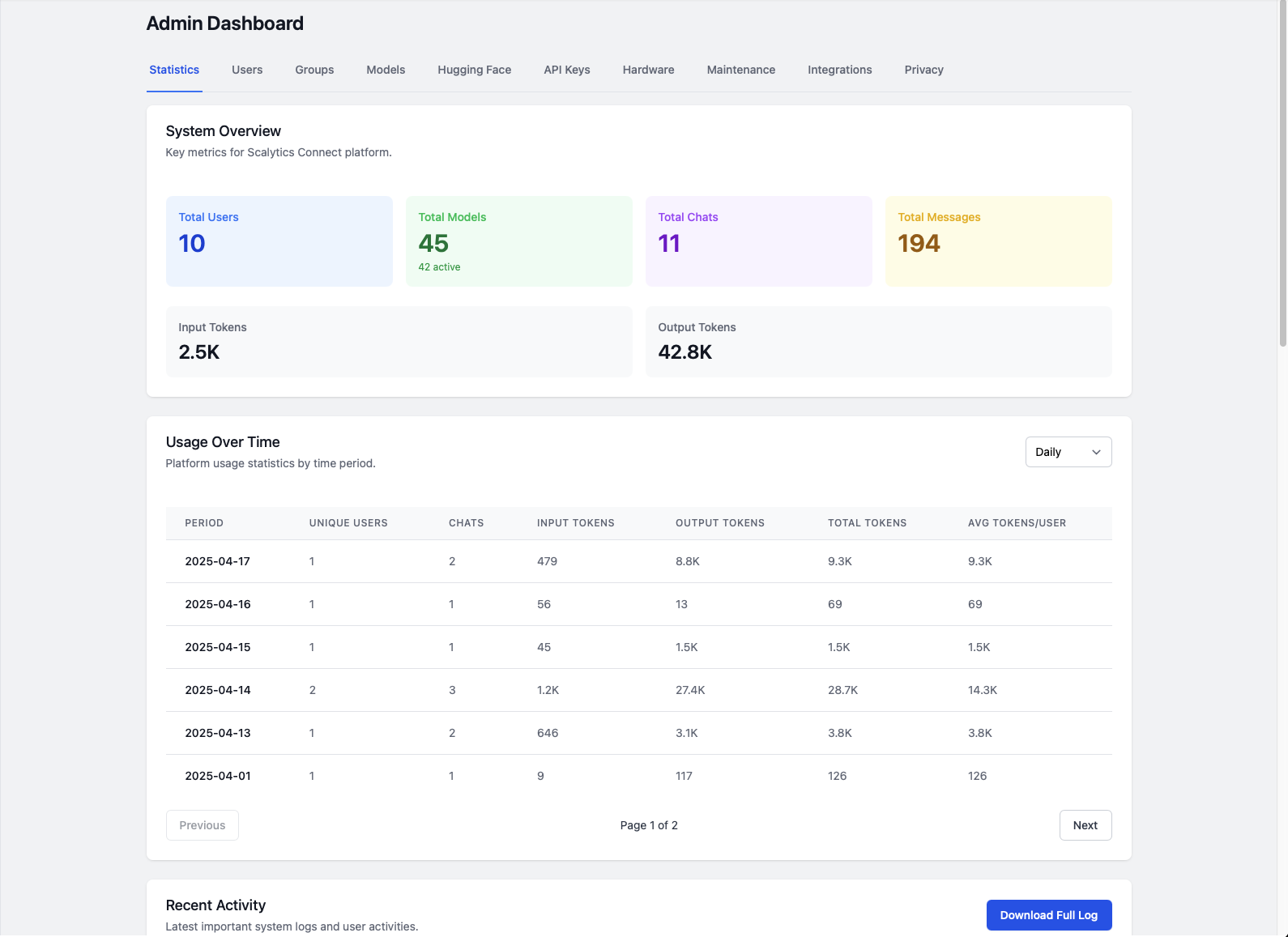
1. Stateless Models, Blocking Requests, and the Multi-User Bottleneck
Open models like Llama and Mistral are fundamentally stateless. This makes them great at inference performance—but terrible at handling more than one request at a time.
Why? Because:
- Inference is blocking: the model is busy until it finishes generating.
- There's no built-in memory: every prompt must include full context—history, instructions, system prompts—every time.
- There's no queue: users who send requests simultaneously will either wait... or collide.
That’s fine if you’re building a personal assistant on localhost. It’s a problem if you want to serve dozens—or hundreds—of concurrent users in a secure, explainable way.
Scalytics Connect introduces the queuing and routing layer that’s missing.
We maintain session-aware queues, route jobs to available model workers, and isolate requests per user and project. This means you can:
- Run multiple concurrent chats against the same model
- Control memory usage and token limits per session
- Avoid GPU deadlocks, retries, or dropped requests
And it all happens behind the scenes—no special client logic, no messy configs.
2. The Auri System Prompt: How We Enforce Enterprise-Grade Behavior
Most people think of system prompts as optional. At Scalytics, they’re foundational.
We enforce what we call the Scala Prompt, a standardized set of behavioral constraints that every model follows in regulated environments. This includes:
- Only responding based on provided context
- Never making up facts or pulling in external knowledge
- Avoiding advice in restricted domains (finance, medical, legal)
- Refusing to store, remember, or leak sensitive inputs
It’s like content moderation, data protection, and model guardrails rolled into one.
In Scalytics Connect, this is configurable per model. When enabled:
- We append the Scala Prompt after the user’s custom system prompt—ensuring user intent is preserved, but guardrails are enforced.
- We log the full effective prompt (user + system) for auditability.
- We block unsafe behavior at inference-time, not just post hoc filtering.
This isn’t prompt engineering. It’s runtime policy enforcement.
3. The Context Window Problem: And Why We Had to Build a Token-Aware Router
LLMs don’t have memory. They have a token limit.
Every model—Llama 3 (8k), Mixtral (32k), GPT-4 (128k)—has a maximum number of tokens it can accept. That includes:
- The system prompt
- The conversation history
- The current message
- And the space for the model's reply
Go over that limit? You’ll either get a failure, an error, or a mysterious truncation that breaks the answer quality.
Scalytics Connect solves this with a token-aware Inference Router.
Before we send anything to the model, we:
- Check total prompt size (system prompt + chat history + current input)
- Summarize older turns if the prompt crosses a warning threshold
- Truncate selectively if summarization isn’t enabled or enough
- Validate the final token count—before inference, not after
- Reject and log if even the compressed prompt exceeds the limit
This lets teams use large language models predictably—without broken responses or silent failures.
4. Global Privacy Mode: You Decide Where Data Can Go
One of the most powerful features in Scalytics Connect is also the simplest: Global Privacy Mode.
With a single toggle, administrators can:
- Disable all external APIs and models
- Force all inference to happen on local infrastructure
- Prevent any data from being sent outside the trusted boundary
It’s enforced across:
- Model routing
- Provider selection
- User preferences
- Frontend access
So you’re not relying on user discipline or dev environment hacks. It’s built into the runtime.
5. Observability and Trust: You Can’t Secure What You Can’t See
Finally, every part of Connect is built to be observable. That means:
- Full request logs: who asked what, using which model, at what time
- Token counts: before and after summarization or truncation
- Effective prompts: user + system + enforced guardrails
- Output tokens and generation time
- Warnings when context limits are approaching
These logs don’t just help with debugging. They support compliance, audit readiness, and internal trust—especially when multiple departments or legal teams are involved.
The Future of LLMs Isn’t Just Open. It’s Operable.
Open-weight models are powerful. But until you can run them securely, explainably, and across teams, they’re just experiments.
Scalytics Connect is how we make them operational.
It’s not federated—yet. But it’s already handling the hard part: managing stateless models across multiple users with privacy enforcement, memory management, and runtime guarantees.
Whether you’re building a private assistant for your product team, deploying AI workflows in healthcare, or evaluating local inference in defense or finance, Connect gives you the layer you need between model and user.
About Scalytics
Built on distributed computing principles and modern virtualization, Scalytics Connect orchestrates resource allocation across heterogeneous hardware configurations, optimizing for throughput and latency. Our platform integrates seamlessly with existing enterprise systems while enforcing strict isolation boundaries, ensuring your proprietary algorithms and data remain entirely within your security perimeter.
With features like autodiscovery and index-based search, Scalytics Connect delivers a forward-looking, transparent framework that supports rapid product iteration, robust scaling, and explainable AI. By combining agents, data flows, and business needs, Scalytics helps organizations overcome traditional limitations and fully take advantage of modern AI opportunities.
If you need professional support from our team of industry leading experts, you can always reach out to us via Slack or Email.